
How to choose the best speech-to-text API
With more speech-to-text APIs on the market than ever before, how do you choose the best one for your product or use case? Answering these six questions is a great starting point.



Speech-to-text APIs convert spoken words into written text through developer-friendly interfaces. The field has grown exponentially, and market projections show it’s expected to reach a market volume of US$73 billion by 2031. These APIs now power everything from AI meeting assistants to call center analytics. With dozens of providers available, choosing the right API requires understanding key evaluation criteria.
This guide walks through everything you need to know about speech-to-text APIs—from how they work and when to use them, to the specific questions that will help you identify the best solution for your needs. We’ll cover the technical foundations, explore real-world applications, and provide a framework for evaluating different options based on accuracy, features, support, and other critical factors.
What is a speech-to-text API?
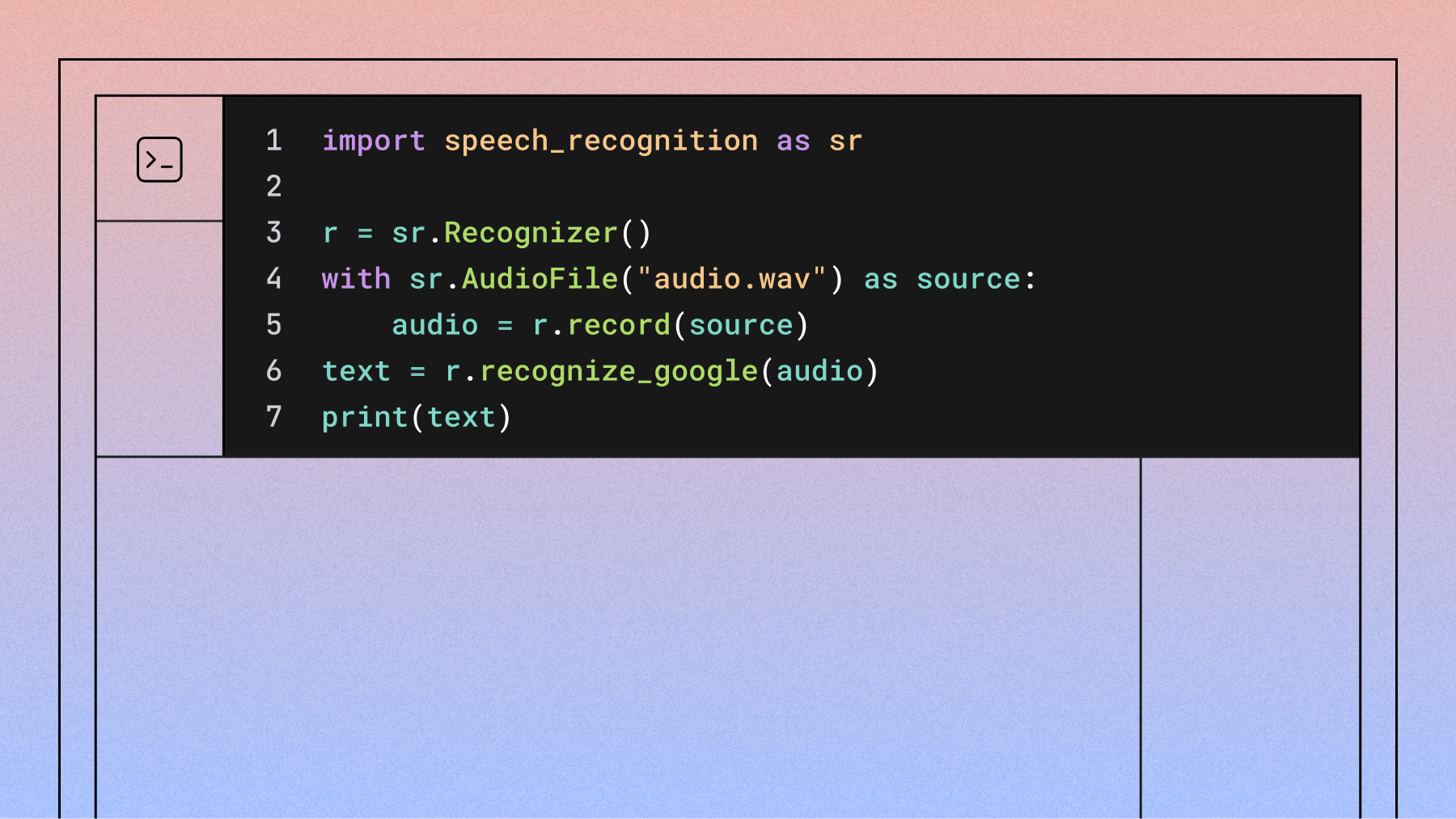
A speech-to-text API converts spoken words into written text through a simple developer interface. You send audio files or streams to an API endpoint and receive accurate transcriptions back. This eliminates the need to build complex Voice AI models from scratch.
How do speech-to-text APIs work?
The process is fairly simple from a developer’s perspective. Your application makes a request to the API provider’s endpoint, sending an audio file or a live stream of audio data. The provider’s AI models then process the audio, converting the spoken words into text. The API returns this transcript to your application, often including additional data like word-level timestamps, speaker labels, and confidence scores. The entire underlying infrastructure for processing the audio at scale is managed by the API provider.
Types of speech-to-text API architectures
Not all speech-to-text APIs use the same architecture. Your choice depends on your specific use case and processing requirements.
Three main API types handle different audio processing needs:
- Asynchronous APIs: Process pre-recorded files and return complete transcripts. Ideal for media content, call recordings, and batch processing.
- Real-time streaming APIs: Handle live audio through persistent connections, returning incremental transcripts. Essential for live captioning and voice assistants. Learn more in the real-time streaming documentation.
- On-premise deployment: Run Voice AI models within your private infrastructure for strict security requirements.
The choice between these architectures impacts not just your technical implementation but also your cost structure and scalability. Real-time APIs typically have different pricing models than batch processing. On-premise solutions require significant upfront infrastructure investment but may offer lower long-term costs for high-volume use cases.
Common use cases for speech-to-text APIs
Speech-to-text APIs power voice features across every industry. Here are the most common applications:
- Call centers: Companies like CallSource and Ringostat transcribe customer interactions to improve agent performance.
- Media platforms: Services like Veed and Podchaser generate captions and searchable transcripts.
- Meeting intelligence: Tools like Circleback AI create automated summaries and action items.
Getting started with a speech-to-text API
Integrating a speech-to-text API is usually a quick process. Most providers, including AssemblyAI, follow a similar developer workflow:
- Get an API key: Sign up for a free account to get an API key that authenticates your requests.
- Read the documentation: Review the API docs to understand the available endpoints, parameters, and SDKs for your programming language.
- Make your first request: Send your first audio file to the API and get a transcript back. From there, you can explore more advanced features.
How accurate is the API?
Accuracy is the most critical factor when comparing speech-to-text APIs. A 2024 survey of over 200 tech leaders found accuracy and quality were among the top three most important factors when evaluating an AI vendor.
Word Error Rate (WER) — and its limitations
Word Error Rate (WER) is the standard benchmark for measuring ASR accuracy. It is calculated as the percentage of words that were inserted, deleted, or substituted compared to a human-verified reference transcript. But as models like Universal-3 Pro push accuracy beyond what human transcriptionists can reliably produce, traditional WER benchmarks are revealing a critical flaw: the ground truth itself may be wrong.
AssemblyAI’s own research found that when Universal-3 Pro showed disproportionate “insertions” — words the AI added that weren’t in the human reference — the vast majority of those insertions were actually correct. They were genuine words spoken in the audio that the human transcriptionist had missed. In other words, a lower WER score can actually reflect a worse model if the reference transcripts contain errors.
Three types of errors affect WER scores:
- Insertions (hallucinations): Words added by the AI that were not spoken.
- Deletions: Words the AI missed that were spoken.
- Substitutions: Incorrect words transcribed (e.g., “Cadillac” transcribed as “cataracts”).
How to run an accurate benchmark
The most reliable way to test accuracy is to build your own benchmark using your own audio data — not public leaderboards, which may not reflect your specific use case, speaker demographics, or acoustic conditions.
Follow this methodology:
- Collect 10–20 representative audio files that reflect your real-world conditions (noise levels, accents, domain vocabulary).
- Obtain human-verified reference transcriptions (your ground truth).
- Submit the same files to each API you’re evaluating.
- Normalize outputs using the Whisper Normalizer, which lowercases text, removes punctuation, and handles common semantic mappings (e.g., “two” vs. “2”).
- Calculate WER using a library like jiwer.
AssemblyAI has published an open-source GitHub repository with tooling for building internal benchmarking pipelines, including truth file correction and semantic word list generation.
Critical caveat: ground truth quality
Modern AI models can now outperform human transcriptionists, particularly on difficult audio with background noise, strong accents, or overlapping speakers. If your human reference transcripts contain errors, the model that most closely matches those errors will appear to win — even if it is objectively less accurate.
Always validate your ground truth files carefully. When a model produces an “insertion” your reference doesn’t have, listen to the audio before counting it as an error. It may be a correct transcription of a word the human transcriptionist missed.
Semantic equivalence and normalization
Models using LLM-based decoders may produce stylistic variations — “alright” vs. “all right”, “healthcare” vs. “health care”, “COVID-19” vs. “covid 19” — that count as WER errors despite having identical meaning. The Whisper Normalizer handles many common cases, but domain-specific variations require custom semantic word lists to prevent unfairly penalizing newer, more capable models.
Evaluate streaming and batch models separately
Streaming and asynchronous transcription models solve fundamentally different problems at different levels of architectural complexity. Comparing their WER scores directly is misleading. Run separate benchmarks for each architecture type and weight the results according to which matters most for your application.
Using visual diff tools alongside WER
For a quick qualitative check alongside WER scores, visual diff tools like Diffchecker let you paste two transcripts side-by-side and see exactly which words were added, removed, or changed. This is especially useful for spotting patterns that aggregate error rates can obscure.
When reviewing a diff, apply the updated lens from modern WER research:
- Correct insertions: If the AI adds words not in your reference, listen to the audio before labeling them errors. Your ground truth may have gaps.
- Semantic variations: Note differences like “alright” vs. “all right” separately from genuine mistakes — these are formatting choices, not accuracy failures.
- Proper nouns and domain terms: Check whether names, technical vocabulary, and acronyms are handled correctly across providers.
- Accent and dialect handling: Does accuracy degrade on speakers with specific accents or dialects? A 2022 study found a 16 percentage-point accuracy gap between Black and white speakers across major ASR systems.
The key shift: treat diff output as a starting point for investigation, not a final verdict. A transcript with more highlighted differences may actually be more accurate than one that closely mirrors an error-prone human reference.
What additional features and models does the API offer?
Beyond core transcription, you can enable a suite of Speech Understanding models to extract more value from your audio data. Common models include:
- Summarization: Generate summaries of audio files in various formats.
- Speaker Diarization: Identify and label different speakers in the audio.
- PII Redaction: Automatically detect and remove personally identifiable information.
- Auto Chapters: Automatically segment audio into chapters with summaries.
- Topic Detection: Classify audio content based on the IAB standard.
- Content Moderation: Detect sensitive or inappropriate content.
- Paragraph and Sentence Segmentation: Automatically break transcripts into readable paragraphs and sentences.
- Sentiment Analysis: Analyze the sentiment of each sentence.
- Confidence Scores: Get word-level and transcript-level confidence scores.
- Automatic Punctuation and Casing: Improve readability with automatic formatting.
- Profanity Filtering: Censor profane words in the transcript.
- Entity Detection: Identify named entities like people, places, and organizations.
- Accuracy Boosting (Keyterms & Custom Vocabulary): Improve accuracy for specific terms and phrases.
When choosing a speech-to-text API, you should also evaluate how often new features are released and how often the models are updated.
The best speech-to-text APIs maintain dedicated AI research teams for continuous model improvement. Look for these innovation indicators:
- Regular model updates and improvements.
- Transparent changelog with detailed release notes.
- Active research publications and breakthroughs.
Make sure you check the API’s changelog and updates, which should be transparent and easily accessible. For example, AssemblyAI ships updates weekly via its publicly accessible changelog. If an API doesn’t have a changelog, or doesn’t update it very often, this is a red flag.
What kind of support can you expect?
Too often, APIs offered by big tech companies like Google Cloud and AWS go unsupported and are infrequently updated.
It’s inevitable that you’ll have questions as you build new features, which is why an industry survey found that API and developer resources are a top-five factor for tech leaders when choosing an AI vendor. This is why you should look for an API that offers dedicated, quick support to you and your team of developers. Support should be offered 24/7 via multiple channels such as email, messaging, or Slack.
You should be assigned a dedicated account manager and support engineer that offer integration support, provide quick turnaround on support requests, and help you figure out the best features to integrate.
Also consider:
- Uptime reports (should be at or near 100%).
- Customer reviews and awards on sites like G2.
- Accessible changelog with detailed and frequent updates, as discussed above.
- Quick, helpful support via multiple channels.
Does the API offer transparent pricing and documentation?
API pricing shouldn’t be a guessing game. All APIs you are considering should offer transparent, easy-to-decipher pricing as well as volume discounts for high levels of usage. A free trial for the API that lets you explore the API before committing to purchase is even better.
Watch for these common pricing and integration challenges:
- Hidden costs: Google Cloud requires data hosting in GCP Buckets, increasing total expenses.
- File size limits: OpenAI Whisper’s 25MB chunks complicate large file processing.
- Documentation quality: Poor API documentation signals difficult integration.
How secure is your data?
Data security becomes critical when processing sensitive voice data, especially as research shows the average cost of a healthcare data breach has reached $10.93 million per incident. Evaluate these essential security measures:
- Encryption: End-to-end encryption for data in transit and at rest.
- Compliance certifications: SOC 2 Type 2, GDPR compliance as needed.
- Data retention policies: Clear policies on how long audio and transcripts are stored.
- Access controls: Robust authentication and authorization mechanisms.
Is innovation a priority?
The field of speech-to-text recognition is in a state of constant innovation. Any API you consider should have a strong focus on AI research.
Also ensure that the API directs its research toward frequent model updates. The field of Voice AI is advancing rapidly, and even mature features like Speaker Diarization and Sentiment Analysis benefit from continuous improvement. Choose a provider that is committed to pushing the boundaries of accuracy and functionality across their entire suite of models.
The API’s changelogs are a good way to determine the difference between an API stating they prioritize innovation and an API demonstrating that they are truly innovating. Pay attention to descriptions of model versioning and how they split up model updates.
For example, AssemblyAI ships detailed updates for all its models and features via its changelog regularly. Others may have a changelog but give limited insight.
Choosing the right speech-to-text API
Here are the key questions to ask when evaluating speech-to-text APIs:
- How accurate is the API?
- What additional features does the API offer?
- What kind of support can you expect?
- Does the API offer transparent pricing and documentation?
- How secure is your data?
- Is innovation a priority?
Taking the time to do research now will set you up for long-term success with your speech-to-text API partner.
If you’re interested in trying our API, get your free speech-to-text API key and transcribe your own audio data.
Frequently asked questions about speech-to-text APIs
Are there free speech-to-text APIs?
Yes, many providers offer free tiers, and open source models like Whisper are available. Commercial APIs handle infrastructure complexity, while open source requires self-hosting and maintenance.
How is accuracy measured for speech-to-text?
Speech-to-text accuracy is primarily measured using Word Error Rate (WER), which compares API transcripts to human-verified reference text to calculate the percentage of insertions, deletions, and substitutions. However, WER has known limitations when AI models outperform the human transcriptionists who created the reference data — see the accuracy section above for guidance on running a rigorous benchmark.
What’s the difference between real-time and asynchronous transcription?
Asynchronous transcription processes pre-recorded files and returns complete transcripts, while real-time transcription converts live audio streams into text as speech happens. These architectures have different accuracy profiles and should be benchmarked separately.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts



.png)